class: center, middle, inverse, title-slide # The Joy of Data Wrangling in R ## <br> Crossing the Tidyverse ### Christopher Callaghan - CORE Lab ### 2019-08-07 --- # Motivation <br> .center[ 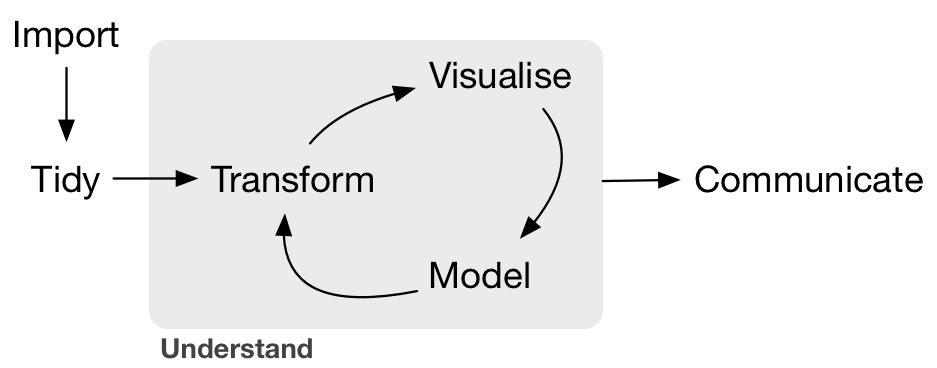 ] <small> Source: Wickham, Hadley, and Garrett Grolemund. 2017. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. 1st ed. O’Reilly Media, Inc. </small> --- # Overview 1. Introduction to the **tidyverse** 🌌 2. Ingesting data with **readr** 📖 3. Data wrangling in **dplyr** 🧰 4. Working with text with **stringr** 🔤 5. Tidying data with **tidyr** 🧹 --- # tidyverse 101 A collection of R packages designed to for data science. - Shared grammar and design - Wide range of applications Install: ```r install.packages("tidyverse") ``` Launch: ```r library(tidyverse) ``` --- # Loading Data with **readr** 📖 ```r url <- "https://raw.githubusercontent.com/fivethirtyeight/russian-troll-tweets/master/IRAhandle_tweets_1.csv" df <- read_csv(file = url) ``` ``` ## # A tibble: 243,891 x 21 ## external_author… author content region language publish_date ## <dbl> <chr> <chr> <chr> <chr> <chr> ## 1 9.06e17 10_GOP "\"We … Unkno… English 10/1/2017 1… ## 2 9.06e17 10_GOP Marsha… Unkno… English 10/1/2017 2… ## 3 9.06e17 10_GOP Daught… Unkno… English 10/1/2017 2… ## 4 9.06e17 10_GOP JUST I… Unkno… English 10/1/2017 2… ## 5 9.06e17 10_GOP 19,000… Unkno… English 10/1/2017 2… ## 6 9.06e17 10_GOP "Dan B… Unkno… English 10/1/2017 2… ## 7 9.06e17 10_GOP 🐝🐝🐝 ht… Unkno… English 10/1/2017 2… ## 8 9.06e17 10_GOP '@Sena… Unkno… English 10/1/2017 2… ## 9 9.06e17 10_GOP As muc… Unkno… English 10/1/2017 3… ## 10 9.06e17 10_GOP After … Unkno… English 10/1/2017 3… ## # … with 243,881 more rows, and 15 more variables: harvested_date <chr>, ## # following <dbl>, followers <dbl>, updates <dbl>, post_type <chr>, ## # account_type <chr>, retweet <dbl>, account_category <chr>, ## # new_june_2018 <dbl>, alt_external_id <dbl>, tweet_id <dbl>, ## # article_url <chr>, tco1_step1 <chr>, tco2_step1 <chr>, ## # tco3_step1 <lgl> ``` --- # Data wrangling in **dplyr** 🧰 - How to handle extraneous variables? - Can I subset and rearrange my observations? - What is the easiest way to add new variables to my data set? - How can I use **dplyr** to gain quick insights about my data? .center[  ] --- # How to handle extraneous variables? ```r df %>% * select(author, * content, * language, * publish_date, * post_type, * account_category) ``` ``` ## # A tibble: 243,891 x 6 ## author content language publish_date post_type account_category ## <chr> <chr> <chr> <chr> <chr> <chr> ## 1 10_GOP "\"We have a si… English 10/1/2017 1… <NA> RightTroll ## 2 10_GOP Marshawn Lynch … English 10/1/2017 2… <NA> RightTroll ## 3 10_GOP Daughter of fal… English 10/1/2017 2… RETWEET RightTroll ## 4 10_GOP JUST IN: Presid… English 10/1/2017 2… <NA> RightTroll ## 5 10_GOP 19,000 RESPECTI… English 10/1/2017 2… RETWEET RightTroll ## 6 10_GOP "Dan Bongino: \… English 10/1/2017 2… <NA> RightTroll ## 7 10_GOP 🐝🐝🐝 https://t.c… English 10/1/2017 2… RETWEET RightTroll ## 8 10_GOP '@SenatorMenend… English 10/1/2017 2… <NA> RightTroll ## 9 10_GOP As much as I ha… English 10/1/2017 3… <NA> RightTroll ## 10 10_GOP After the 'geno… English 10/1/2017 3… <NA> RightTroll ## # … with 243,881 more rows ``` --- # Can I subset and rearrange my observations? ```r df %>% select(author, content, language, publish_date, post_type, account_category) %>% * filter(post_type == "RETWEET" & language == "English") %>% * arrange(publish_date) ``` ``` ## # A tibble: 7 x 6 ## author content language publish_date post_type account_category ## <chr> <chr> <chr> <chr> <chr> <chr> ## 1 ALECMO… "Pusha T's firs… English 1/1/2016 18… RETWEET LeftTroll ## 2 ANTONH… None you weirdo… English 1/1/2016 18… RETWEET LeftTroll ## 3 ANTONH… James Surowieck… English 1/1/2016 18… RETWEET LeftTroll ## 4 ADRGRE… Gospel music--s… English 1/1/2016 18… RETWEET LeftTroll ## 5 ADRGRE… If Kim Kardashi… English 1/1/2016 18… RETWEET LeftTroll ## 6 ADRGRE… My best RTs thi… English 1/1/2016 18… RETWEET LeftTroll ## 7 AMELIE… "Join us LIVE o… English 1/1/2017 0:… RETWEET RightTroll ``` --- # What is the easiest way to add new variables to my data set? ```r df %>% select(author, content, language, publish_date, post_type, account_category) %>% filter(post_type == "RETWEET" & language == "English") %>% * mutate(political = if_else(account_category == "LeftTroll" | * account_category == "RightTroll", * "Political", "Not Political")) ``` ``` ## # A tibble: 7 x 7 ## author content language publish_date post_type account_category political ## <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 10_GOP Daught… English 10/1/2017 2… RETWEET RightTroll Political ## 2 10_GOP 19,000… English 10/1/2017 2… RETWEET RightTroll Political ## 3 10_GOP 🐝🐝🐝 ht… English 10/1/2017 2… RETWEET RightTroll Political ## 4 10_GOP BREAKI… English 10/11/2017 … RETWEET RightTroll Political ## 5 10_GOP Becaus… English 10/11/2017 … RETWEET RightTroll Political ## 6 10_GOP I am a… English 10/11/2017 … RETWEET RightTroll Political ## 7 10_GOP Do you… English 10/12/2017 … RETWEET RightTroll Political ``` --- # How can I use **dplyr** to gain quick insights about my data? ```r df %>% select(author, content, language, publish_date, post_type, account_category) %>% filter(post_type == "RETWEET" & language == "English") %>% mutate(political = if_else(account_category == "LeftTroll" | account_category == "RightTroll", "Political", "Not Political")) %>% * group_by(political) %>% * summarise(political_volume=n()) ``` ``` ## # A tibble: 2 x 2 ## political political_volume ## <chr> <int> ## 1 Not Political 19969 ## 2 Political 82060 ``` --- # How can I use **dplyr** to gain quick insights about my data? ```r df %>% select(author, content, language, publish_date, post_type, account_category) %>% * filter(language == "English") %>% mutate(political = if_else(account_category == "LeftTroll" | account_category == "RightTroll", "Political", "Not Political")) %>% group_by(political) %>% summarise(political_volume=n()) ``` ``` ## # A tibble: 2 x 2 ## political political_volume ## <chr> <int> ## 1 Not Political 41423 ## 2 Political 148829 ``` --- # Working with Text in stringr 🔤 - Why should I care about handing casing? - How do I determine the length of string? - What if I want to manipulate a string? - Can I find text patterns? - How do I extract patterns from strings? .center[  ] --- # Why should I care about handing casing? ```r string1 <- "Chris loves stringr" string2 <- "Chris loves Stringr" string1 == string2 ``` ``` ## [1] FALSE ``` ```r string1 <- str_to_upper(string1) string2 <- str_to_upper(string2) string1 == string2 ``` ``` ## [1] TRUE ``` --- # How do I determine the lenght of string? ```r df %>% select(content) %>% top_n(1) %>% * str_length() ``` ``` ## Selecting by content ``` ``` ## [1] 49 ``` ```r df %>% select(author, content, publish_date, post_type, account_category) %>% * mutate(content_length = str_length(content)) ``` ``` ## # A tibble: 5 x 6 ## author content publish_date post_type account_category content_length ## <chr> <chr> <chr> <chr> <chr> <int> ## 1 10_GOP "\"We have… 10/1/2017 1… <NA> RightTroll 156 ## 2 10_GOP Marshawn L… 10/1/2017 2… <NA> RightTroll 140 ## 3 10_GOP Daughter o… 10/1/2017 2… RETWEET RightTroll 143 ## 4 10_GOP JUST IN: P… 10/1/2017 2… <NA> RightTroll 145 ## 5 10_GOP 19,000 RES… 10/1/2017 2… RETWEET RightTroll 83 ``` --- # How do I determine the lenght of string? ```r df %>% select(author, content, publish_date, post_type, account_category) %>% * mutate(content_length = str_length(content)) %>% group_by(account_category) %>% * summarise(average_tweet_len = mean(content_length), * max_tweet_len = max(content_length), * min_tweet_len = min(content_length)) ``` ``` ## # A tibble: 8 x 4 ## account_category average_tweet_len max_tweet_len min_tweet_len ## <chr> <dbl> <int> <int> ## 1 Commercial 91.1 164 23 ## 2 Fearmonger 78.3 151 9 ## 3 HashtagGamer 73.9 168 3 ## 4 LeftTroll 103. 778 1 ## 5 NewsFeed 106. 163 32 ## 6 NonEnglish 100. 250 4 ## 7 RightTroll 115. 816 4 ## 8 Unknown 74.0 164 8 ``` --- # What if I want to manipulate a string? ```r df %>% select(author, content, publish_date, post_type, account_category) %>% * mutate(handles = str_c("@", author), content_length = str_length(content)) ``` ``` ## # A tibble: 243,891 x 7 ## author content publish_date post_type account_category handles ## <chr> <chr> <chr> <chr> <chr> <chr> ## 1 10_GOP "\"We … 10/1/2017 1… <NA> RightTroll @10_GOP ## 2 10_GOP Marsha… 10/1/2017 2… <NA> RightTroll @10_GOP ## 3 10_GOP Daught… 10/1/2017 2… RETWEET RightTroll @10_GOP ## 4 10_GOP JUST I… 10/1/2017 2… <NA> RightTroll @10_GOP ## 5 10_GOP 19,000… 10/1/2017 2… RETWEET RightTroll @10_GOP ## 6 10_GOP "Dan B… 10/1/2017 2… <NA> RightTroll @10_GOP ## 7 10_GOP 🐝🐝🐝 ht… 10/1/2017 2… RETWEET RightTroll @10_GOP ## 8 10_GOP '@Sena… 10/1/2017 2… <NA> RightTroll @10_GOP ## 9 10_GOP As muc… 10/1/2017 3… <NA> RightTroll @10_GOP ## 10 10_GOP After … 10/1/2017 3… <NA> RightTroll @10_GOP ## # … with 243,881 more rows, and 1 more variable: content_length <int> ``` --- # What if I want to manipulate a string? ```r df %>% select(author, content, publish_date, post_type, account_category) %>% mutate(handles = str_c("@", author), content_length = str_length(content)) %>% * group_by(handles) %>% * summarise(average_tweet_len = mean(content_length), * max_tweet_len = max(content_length), * min_tweet_len = min(content_length)) ``` ``` ## # A tibble: 7 x 4 ## handles average_tweet_len max_tweet_len min_tweet_len ## <chr> <dbl> <int> <int> ## 1 @10_GOP 110. 172 20 ## 2 @1488REASONS 78.2 159 23 ## 3 @1D_NICOLE_ 59.9 134 13 ## 4 @1ERIK_LEE 109 121 97 ## 5 @1LORENAFAVA1 110. 182 34 ## 6 @2NDHALFONION 81 92 75 ## 7 @459JISALGE 129 129 129 ``` --- # Can I find text patterns? ```r df %>% filter(language == "English") %>% select(content) ``` ``` ## # A tibble: 10 x 1 ## content ## <chr> ## 1 "\"We have a sitting Democrat US Senator on trial for corruption and yo… ## 2 Marshawn Lynch arrives to game in anti-Trump shirt. Judging by his sagg… ## 3 Daughter of fallen Navy Sailor delivers powerful monologue on anthem pr… ## 4 JUST IN: President Trump dedicates Presidents Cup golf tournament troph… ## 5 19,000 RESPECTING our National Anthem! #StandForOurAnthem🇺🇸 https://t.c… ## 6 "Dan Bongino: \"Nobody trolls liberals better than Donald Trump.\" Exac… ## 7 🐝🐝🐝 https://t.co/MorL3AQW0z ## 8 '@SenatorMenendez @CarmenYulinCruz Doesn't matter that CNN doesn't repo… ## 9 As much as I hate promoting CNN article, here they are admitting EVERYT… ## 10 After the 'genocide' remark from San Juan Mayor the narrative has chang… ``` --- # Can I find text patterns? ```r df %>% select(author, content, publish_date, account_category) %>% mutate(handles = str_c("@", author), * has_mentions = str_detect(content, "@\\w+")) ``` ``` ## # A tibble: 243,891 x 6 ## author content publish_date account_category handles has_mentions ## <chr> <chr> <chr> <chr> <chr> <lgl> ## 1 10_GOP "\"We have a … 10/1/2017 1… RightTroll @10_GOP TRUE ## 2 10_GOP Marshawn Lync… 10/1/2017 2… RightTroll @10_GOP FALSE ## 3 10_GOP Daughter of f… 10/1/2017 2… RightTroll @10_GOP FALSE ## 4 10_GOP JUST IN: Pres… 10/1/2017 2… RightTroll @10_GOP FALSE ## 5 10_GOP 19,000 RESPEC… 10/1/2017 2… RightTroll @10_GOP FALSE ## 6 10_GOP "Dan Bongino:… 10/1/2017 2… RightTroll @10_GOP FALSE ## 7 10_GOP 🐝🐝🐝 https://t… 10/1/2017 2… RightTroll @10_GOP FALSE ## 8 10_GOP '@SenatorMene… 10/1/2017 2… RightTroll @10_GOP TRUE ## 9 10_GOP As much as I … 10/1/2017 3… RightTroll @10_GOP FALSE ## 10 10_GOP After the 'ge… 10/1/2017 3… RightTroll @10_GOP TRUE ## # … with 243,881 more rows ``` --- # Can I find text patterns? ```r df %>% select(author, content, publish_date, account_category) %>% mutate(handles = str_c("@", author), * has_mentions = str_detect(content, "@\\w+")) %>% * group_by(account_category) %>% * summarise(mentions = sum(has_mentions == TRUE), * no_mentions = sum(has_mentions == FALSE)) ``` ``` ## # A tibble: 8 x 3 ## account_category mentions no_mentions ## <chr> <int> <int> ## 1 Commercial 0 339 ## 2 Fearmonger 52 332 ## 3 HashtagGamer 3492 23857 ## 4 LeftTroll 10404 25668 ## 5 NewsFeed 4 11287 ## 6 NonEnglish 5035 48003 ## 7 RightTroll 15403 99407 ## 8 Unknown 49 559 ``` --- # How do I extract patterns from strings? ```r df %>% select(author, content, publish_date) %>% rename(handle = author, tweet = content) %>% * mutate(first_mention = str_extract(tweet, "@(\\w+)"), * all_mentions = str_extract_all(tweet, "@(\\w+)")) ``` ``` ## # A tibble: 243,891 x 5 ## handle tweet publish_date first_mention all_mentions ## <chr> <chr> <chr> <chr> <list> ## 1 10_GOP "\"We have a sitting De… 10/1/2017 19… @nedryun <chr [1]> ## 2 10_GOP Marshawn Lynch arrives … 10/1/2017 22… <NA> <chr [0]> ## 3 10_GOP Daughter of fallen Navy… 10/1/2017 22… <NA> <chr [0]> ## 4 10_GOP JUST IN: President Trum… 10/1/2017 23… <NA> <chr [0]> ## 5 10_GOP 19,000 RESPECTING our N… 10/1/2017 2:… <NA> <chr [0]> ## 6 10_GOP "Dan Bongino: \"Nobody … 10/1/2017 2:… <NA> <chr [0]> ## 7 10_GOP 🐝🐝🐝 https://t.co/MorL3A… 10/1/2017 2:… <NA> <chr [0]> ## 8 10_GOP '@SenatorMenendez @Carm… 10/1/2017 2:… @SenatorMene… <chr [2]> ## 9 10_GOP As much as I hate promo… 10/1/2017 3:… <NA> <chr [0]> ## 10 10_GOP After the 'genocide' re… 10/1/2017 3:… @CNN <chr [1]> ## # … with 243,881 more rows ``` --- # Tidying data with **tidyr** 🧹 - How do I handle list columns? <br> .center[  ] --- # How do I handle list columns? ```r df %>% mutate(all_mentions = str_extract_all(content, "@(\\w+)")) %>% select(author, publish_date, all_mentions) ``` ``` ## # A tibble: 3 x 3 ## author publish_date all_mentions ## <chr> <chr> <list> ## 1 10_GOP 10/1/2017 19:58 <chr [1]> ## 2 10_GOP 10/1/2017 22:43 <chr [0]> ## 3 10_GOP 10/1/2017 22:50 <chr [0]> ``` ```r df %>% mutate(all_mentions = str_extract_all(content, "@(\\w+)")) %>% select(author, publish_date, all_mentions) %>% * unnest() ``` ``` ## # A tibble: 3 x 3 ## author publish_date all_mentions ## <chr> <chr> <chr> ## 1 10_GOP 10/1/2017 19:58 @nedryun ## 2 10_GOP 10/1/2017 2:52 @SenatorMenendez ## 3 10_GOP 10/1/2017 2:52 @CarmenYulinCruz ``` --- # How do I handle list columns? ```r library(igraph) g <- df %>% mutate(all_mentions = str_extract_all(content, "@(\\w+)"), author = str_c("@", author)) %>% select(author, all_mentions) %>% unnest() %>% * graph_from_data_frame() %>% * set.graph.attribute("density", edge_density(.)) %>% * set.graph.attribute("avg_degree", mean(degree(.))) %>% * set.graph.attribute("avg_clu_coef", transitivity(., "average")) ``` <table class="table table-striped table-condensed" style="margin-left: auto; margin-right: auto;"> <caption>Global Graph Metrics</caption> <thead> <tr> <th style="text-align:right;"> Density </th> <th style="text-align:right;"> Avg..Degree </th> <th style="text-align:right;"> Avg..Clustering.Coefficient </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 4.739 </td> <td style="text-align:right;"> 4.739 </td> </tr> </tbody> </table> --- ## Parting Thoughs and Additional Resources <br> .center[  ] .center[ Happy R learning! 🙋 ]